Self-Validation
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Early stopping via self-validation
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, without the need for any training set. We call these models, such as deep image prior (DIP) and deep decoder (DD), collectively as single-instance deep generative priors (SIDGPs). However, often the successes hinge on appropriate early stopping (see Figure 1), which by far has largely been handled in an ad hoc manner or even by visual inspection.
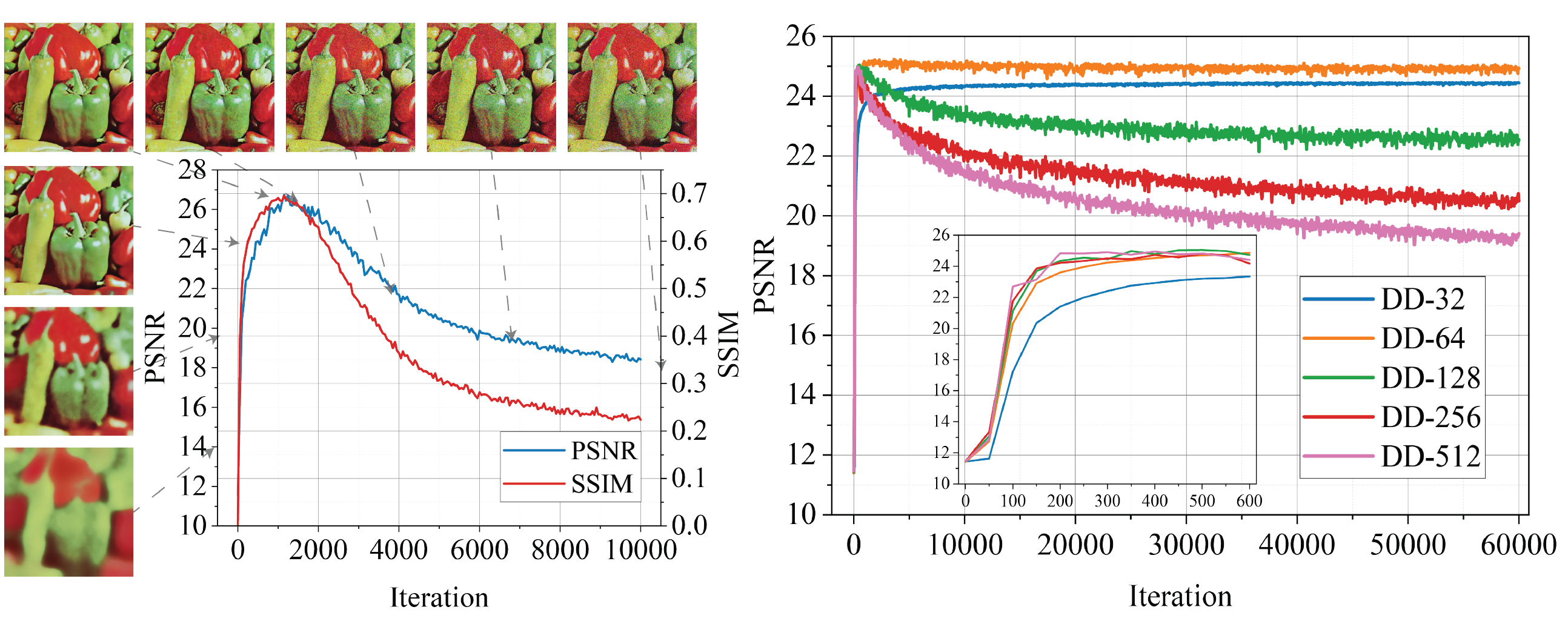
In this paper, we propose the first principled method for early stopping (ES) when applying SIDGPs to image reconstruction, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. On several IR problems and different SIDGPs that we experiment with, our self-validation method is able to reliably detect near-peak performance levels and signal good stopping points (see Figure 2 for an example).
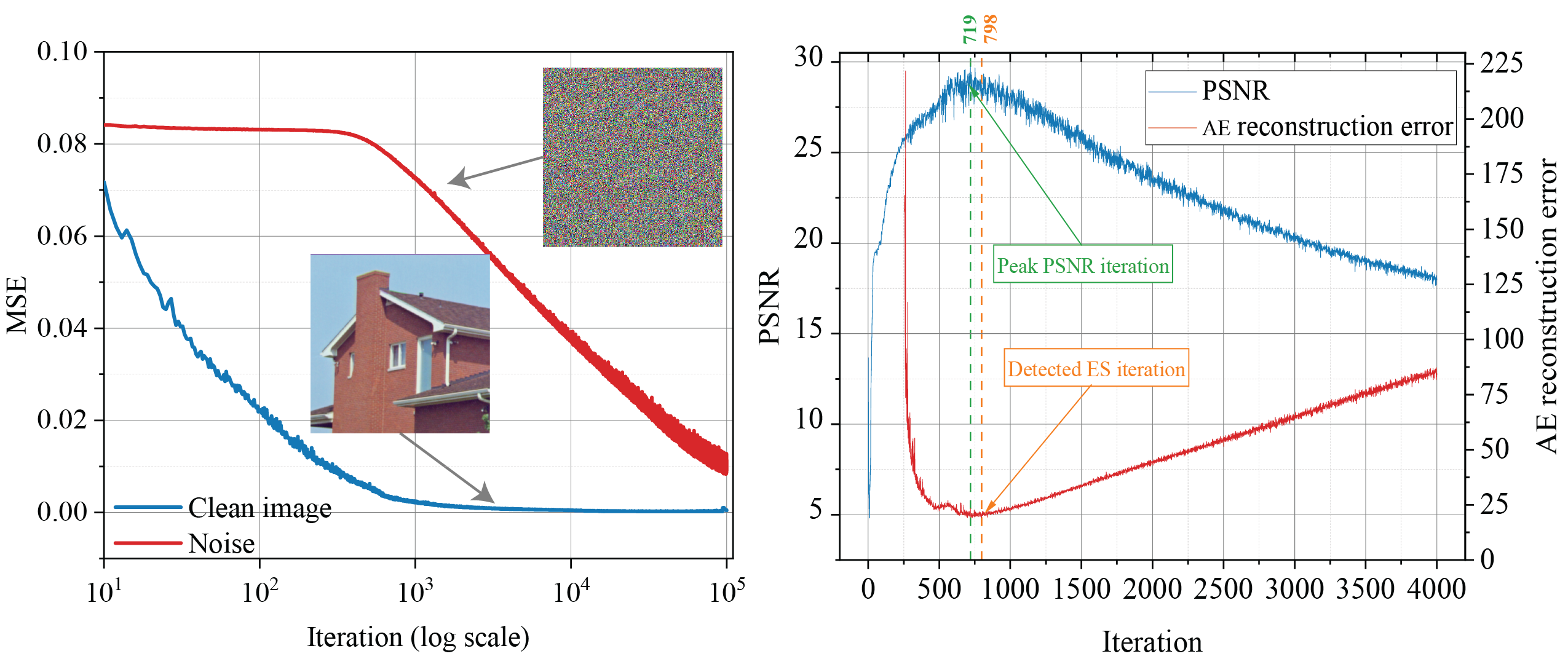
Image denoising
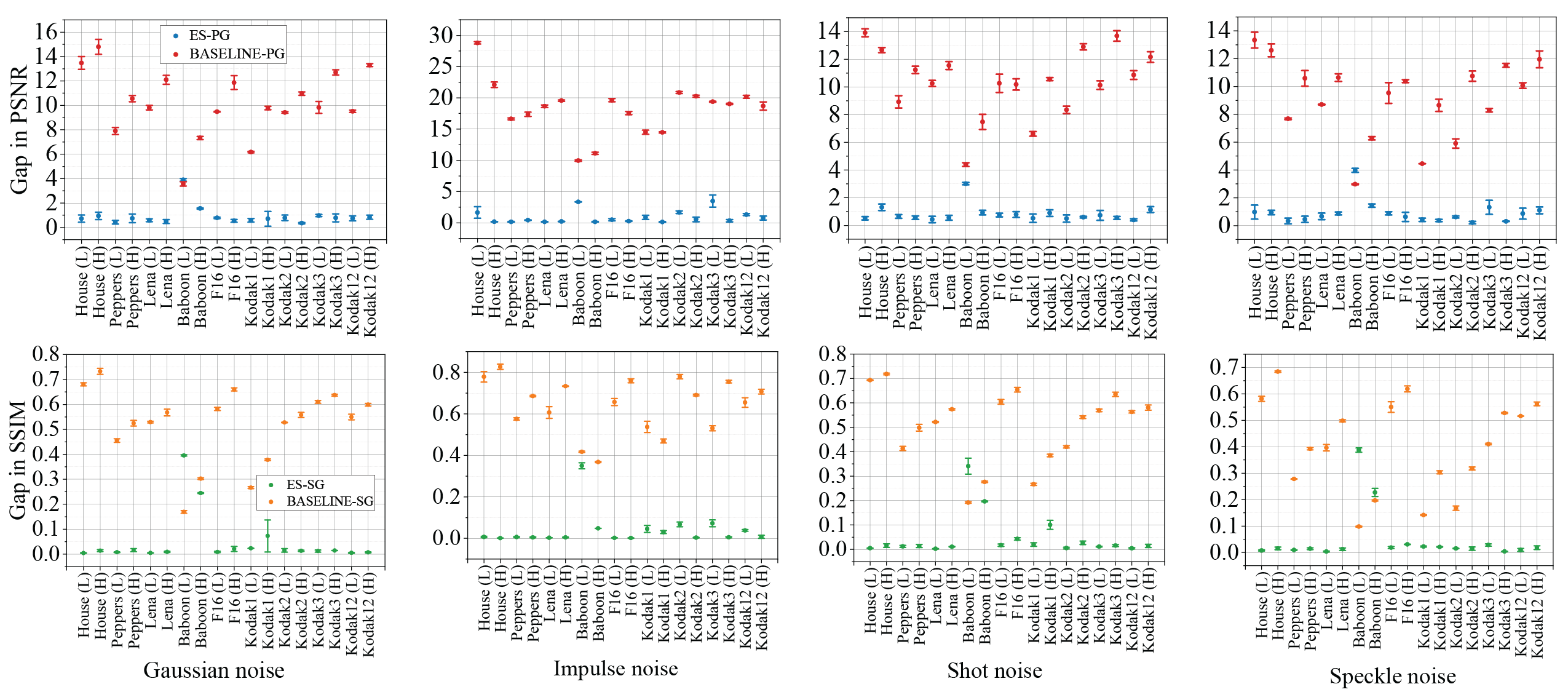
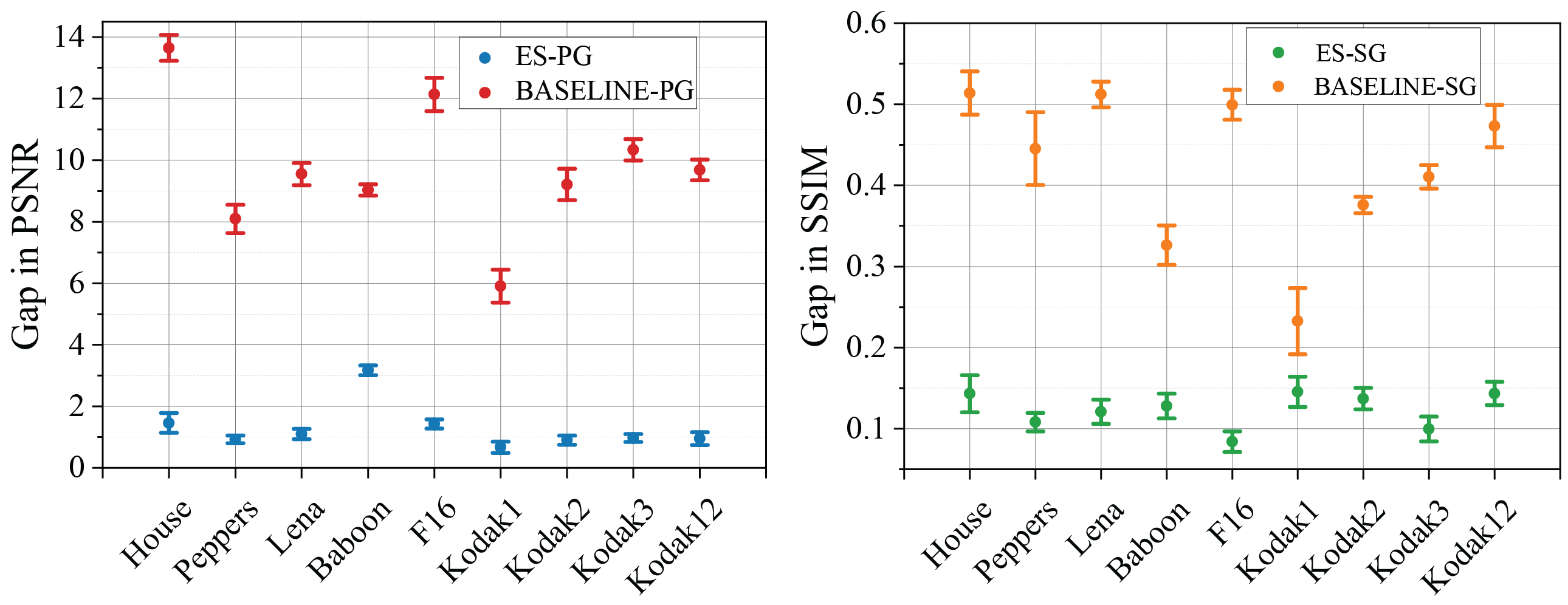
The power of DIP and DD was initially only demonstrated on Gaussian denoising. Here, to make the evaluation more thorough, we also experiment with denoising impulse, shot, and speckle noise, on a standard image denoising dataset (9 images). For each of the 4 noise types, we test a low and a high noise level (details in the Appendix of our paper). To obtain the final degraded results, we run DIP for 150K iterations. The denoising results are measured in terms of the gap metrics that we define—PSNR gap (PG) and SSIM gap (SG)—are summarized in Figure 3.
Our typical detection gap is ≤ 1 measured in ES-PG, and ≤ 0.1 measured in ES-SG. If DIP just runs without ES, the degradation of quality is severe, as indicated by both BASELINE-PG and BASELINE-SG. Evidently, our DIP+AE can save the computation and the reconstruction quality, and return an estimate with near-peak performance for almost all images, noise types, and noise levels that we test.
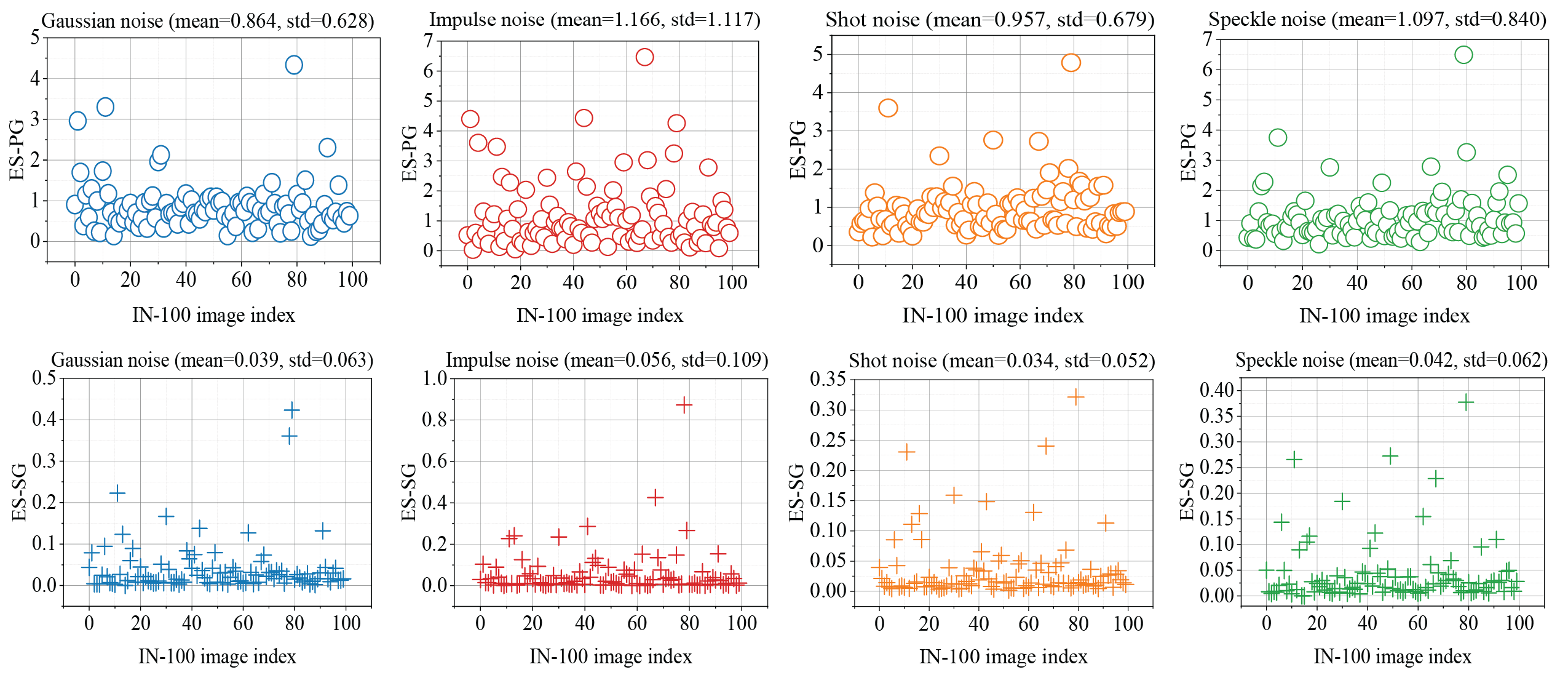
We further confirm the merit of our method on a larger image dataset consisting of 100 randomly selected images from ImageNet, denoted as IN-100. We follow the same evaluation protocol as above, except that we only experiment a medium noise level and we do not estimate the means and standard deviations; the results are reported in Figure 4. It is easy to see that the ES-PGs are concentrated around 1 and the ES-GSs are concentrated around 0.1, consistent with our observation on the small-scale dataset above.
MRI reconstruction
We now test our detection method on MRI reconstruction, a classical medical IR problem involving a nontrivial linear f. Specifically, the model is y = f (x) + ξ = F(x) + ξ , where F is the subsampled Fourier operator and ξ models the noise encountered in practical MRI imaging. Here, we take 8-fold undersampling and choose to parametrize x using a DD. We report the performance here in Figure 5 (results for all randomly selected samples can be found in the Appendix of our paper). Our method is able to signal stopping points that are reasonably close to the peak points, which also yield reasonably faithful reconstruction.
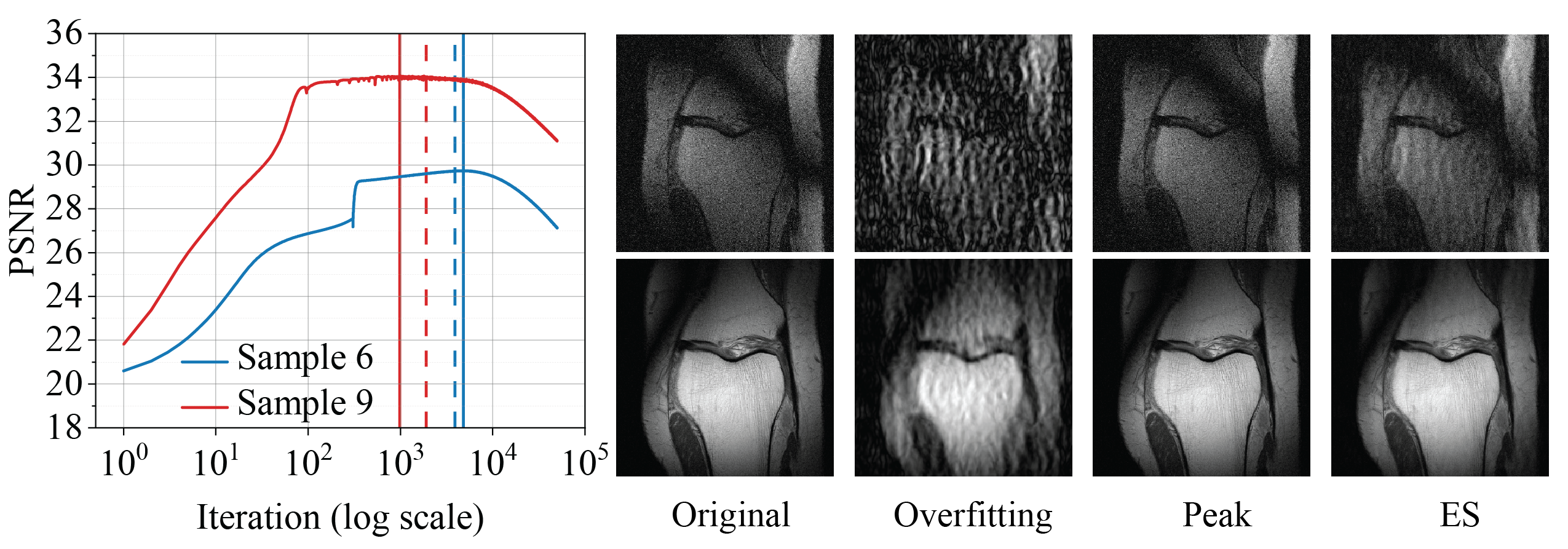
Image regression
Now we turn to SIREN, a recent functional SIDGP model that is designed to facilitate the learning of functions with significant high-frequency components. We consider a simple task from the original task, image regression, but add in some Gaussian noise. Mathematically, the y = x + ε, where ε∼N (0, 0.196). Clearly, when the MLP used in SIREN is sufficiently overparamterized, the noise will also be learned. We test our detection method on this using the same 9-image dataset as in denoising. From Figure 6, we can see again that our method is capable of reliably detecting near-peak performance measured by either ES-PG or ES-SG, much better than without implementing any ES.
Citation/BibTex
More technical details and experimental results can be found in our paper:
@inproceedings{DBLP:conf/bmvc/LiZLPWS21,
author = {Taihui Li and
Zhong Zhuang and
Hengyue Liang and
Le Peng and
Hengkang Wang and
Ju Sun},
title = {Self-Validation: Early Stopping for Single-Instance Deep Generative
Priors},
booktitle = {32nd British Machine Vision Conference 2021, BMVC 2021, Online,
November 22-25, 2021},
pages = {108},
publisher = {BMVA Press},
year = {2021},
url = {https://www.bmvc2021-virtualconference.com/assets/papers/1633.pdf},
timestamp = {Wed, 22 Jun 2022 16:52:45 +0200},
biburl = {https://dblp.org/rec/conf/bmvc/LiZLPWS21.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Contact
- Taihui Li, lixx5027@umn.edu, https://taihui.github.io/
- Zhong Zhuang, zhuan143@umn.edu, https://scholar.google.com/citations?user=rGGxUQEAAAAJ
- Hengyue Liang, liang656@umn.edu, https://hengyuel.github.io/
- Le Peng, peng0347@umn.edu, https://sites.google.com/view/le-peng/
- Hengkang Wang, wang9881@umn.edu, https://www.linkedin.com/in/hengkang-henry-wang-a1b293104/
- Ju Sun, jusun@umn.edu, https://sunju.org/